Overview
- Conceived and implemented an engaging statistical dashboard about the anime industry.
- Utilized graphical representations and time series forecasting to visualise significant historical trends.
- Independently extracted and refined the dataset spanning over 25000 rows through web scraping techniques and pattern matching algorithms.
- Developed a filtering mechanism and hosted the data on a reliable cloud platform.
Story
Building a spider out of nothing, not even knowledge of it, is a task that I took upon myself. It was a project with many up-downs and emmence learnings within them.
Learning above all is the key to greatness and I want to embody that fact as much as possible.
It all started amid the anime craze in India, 2023. The craze had spread to fashion to the point that every 2 out of 5 person that I saw were wearing these off-shoulder tshirts with massive anime art on the back. It looked childish to me but if you see something enough times it gets into your mind and hence, it lead me to my study where I researched about anime.
After the research ended I found that the values that animes like Naruto and One Piece stood for, freedom, discipline and family, really spoke to me on a core level. So I decided to watch a anime but which one to watch?, that was the question that lead to the birth of this project. There were thousands of animes to choose from and hundreds of websites ranking animes, hence I decided to analyse the data to find a anime that I would like to watch. At the time I was learning Tableau as part of my data analyst tech stack and looking for projects to make a dashboard, the anime analysis gave me a chance to practice my newly acquired skill.
The main obstacle for the analysis was the data. Most of the datasets that I found on anime were either incomplete or didn’t have enough attributes. So I decided to make my own dataset. That is how the Anime Spider was born.
I had scraped websites before but never on this scale and volume, the choice of the framework that I would use for scraping the website was critical. There were three frameworks that I primarily found beautifulsoup, selenium and scrapy.
Beautifulsoup is a very simple framework which is used to scrap static websites by parsing there html into a object called soup. It can only work for static websites and has no default pagination facility. Selenium is a web automation framework that is primarily used to test websites or make bots to interact with the web. It’s primary use is not scraping but it can be used to do it. Scrapy is a very complex framework that is primarily used to do industrial level scraping with high volumes and has default pagination facility. Scrapy was the obvious choice here. So I learned building scrappers or rather spiders, that is the professional name for web scrapper.
Before actually making a spider I researched over them a bit and found some interesing facts that I will share with you. Google has thousands of spiders crawling and indexing the internet at all times. That is why it is so accurate at fetching information out of web pages. Also the dark web is nothing more than the part of the internet that has denied access to these spiders. If you think about it this means that before google all of the internet was only the dark web. Moreover websites use files like robots.txt and sitemap.xml to make themselves more reachable by the spiders and help with sales and marketing, this is what people call Search Engine Optimisation (SEO).
After understanding the basics of crawling the web, the legal boundaries and reading about some lawsuites I was ready to make the anime spider. The first step to making a spider in scrapy is to set it up, than you will need to connect your website, write the logic for getting the required html tags and implement some pagination so that your spider can go to the next page. These were the easiest steps, the hardest step was pipelining the input data stream such that it cleans the data automatically so that the spider only outputs clean and ready to use data.
In most data development life cycles, data cleaning and extraction are two different steps, but here they are combined into the spider making it much more powerful. It took extensive regular expression formation and matching to maintain data integrity and prevent any data loss. A quick note here, I have strict no dataloss policy in scraping hence the data cleaning took extra time as I had to take into account all the different formats that the data could come in and handle missing values. Here is a list of all the custom regular expressions that were used.
- [a-zA-Z]{3} [0-9]{1,2}, [0-9]{4} to [a-zA-Z]{3} [0-9]{1,2}, [0-9]{4}
- [a-zA-Z]{3} [0-9]{4}
- [0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{4}-[0-9]{2}-[0-9]{2}
- ([0-9]{4})
- [0-9]{4} to [0-9]{4}
- [a-zA-Z]{3} [0-9]{1,2}, [0-9]{4} to ?
- [a-z]
- [a-zA-Z]{3} [0-9]{1,2}, [0-9]{4} to [a-zA-Z]{3} [0-9]{4}
- [a-zA-Z]{3} [0-9]{1,2}, [0-9]{4} to [0-9]{4}
- [a-zA-Z]* at [0-9]{2}:[0-9]{2} (JST)
- [0-9],? ?\d*:\d*:\d*
- [a-zA-Z]* at Unknown
At this stage the data is fetched & cleaned and now we need to store it. For this I used the generous free tier of PlanetScale. I used a SQL databse for no good reason, any kind of database would work here but SQL is my goto database in most cases.
Running a spider is not a CPU intensive task rather a time intensive task. It can take weeks to scrape a website fully. Hosting the spider was a neccessary step. I found a service provided by the creators of scrapy itself to host my spider for free but I would need to package my spider. Any python enthusiaste would know about a package. It is a importable module, like a battery, that can be used by something else, like in a car. Scrapy already had some inbuilt tools to help with package formation hence, now we have a spider ready deployed.
Production errors are something that are just unexpected and pop up anywhere anytime. There were quite a few errors here but I would not actually call them errors. They were more of the unexpected values that came from different animes as the spider mowed through the website. It would have been easy to make the spider “not care” about those animes but that would have meant dataloss, that is a unforgiveable sin for a data analyst. After some tinkering the spider ran smooth and the data was collected in 2 days with 0% loss.
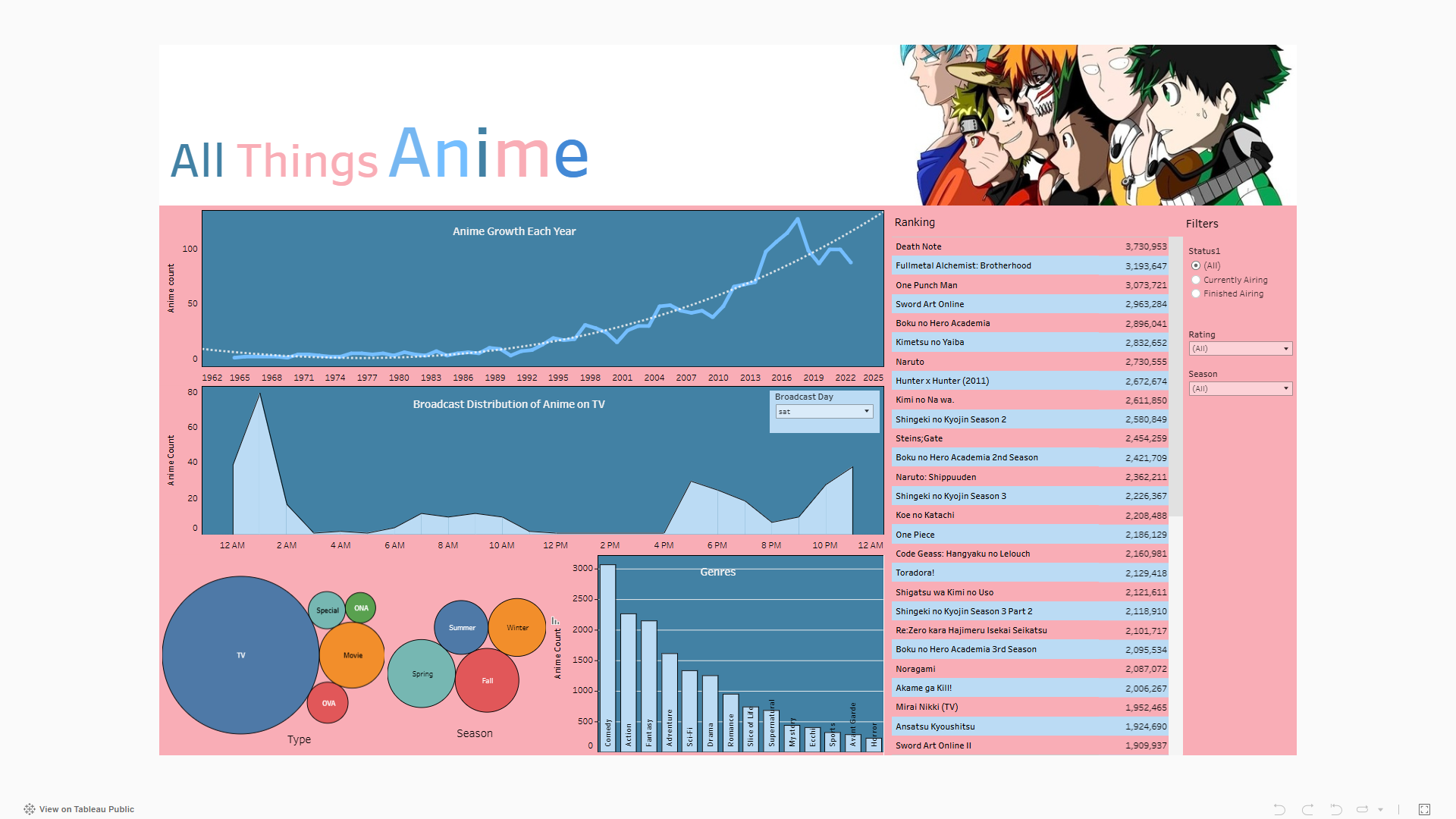
The dashboard made with Tableau is a extra addition to this project which helps in visualizing the database dynamically. Production of it was easy, the hardest part was themeing it so that it was pleasing to look at. The most interesting finding was that most of the top anime on the site were actually quite old and only a handfull of animes from the listing were still airing. That was the whole story of how this project got made. If you have made it this far, thank you so much for giving me your time and attention.